
“Discussion and exchange of views is usually refreshing, stimulating and encouraging, especially when one is in difficulties and worried.”
This quote from the book “The Art of Scientific Investigation” explains one of my motivations for wanting to attend the Deep Learning Indaba in Rwanda.
So if you ask, “did the conference help?”, my answer to that will be an emphatic “yes!”.
I had a range of conversations; some enlightening and interesting, and others I would never have thought of having at an event like the Deep Learning Indaba. Some of these interactions include:
- Getting a 1-1 lecture on generative ai modelling approaches from a fellow attendee
- Having a conversation about balancing building as an engineer and sharing some of my knowledge
- Getting insights into what it is like to do machine learning research in the Kingdom of Saudi Arabia
In the middle of all of this, I also helped give a poster presentation about improving the quality of dense embeddings for Nigerian languages. This is a project I worked on in the first quarter of the year with three amazing people in the Information Retrieval focus group at ML Collective, Nigeria. The project deserves a separate technical post, and that should come later, God willing. The exciting part is the poster got an award as one of the best General Posters at the conference; that is a welcomed morale booster.

Deep Learning Indaba 2026 holds in Nigeria. I expect the application forms will be out next year and I encourage you to apply.
Now, let’s proceed to my top moments.
Top Five Moments
- Learning New Generative Modelling Approaches
- Meeting Luis Serrano
- Realizing Data Access is Harder Than Initially Thought
- Random Learnings
- Getting a Poster Award
Learning New Generative Modelling Approaches
Prior to the conference, I had some exposure to approaches to generative modelling such as Generative Adversarial Networks (GANS), Variational AutoEncoders (VAE), and Diffusion Models. Some of these approaches I learnt from previous projects, work, and the Hands-On Generative AI with Transformers and Diffusion Models book. Attending a session on generative modelling techniques, I expected it to be a refresher session, but it was more than that.
I came across two new concepts: “Normalizing Flows” and “Flow Matching”. As it turns out, they are actually not new; I was only late to the party. Anyone who attends a session where they are seeing a technical concept for the first time will likely agree that it is a bad place to learn. It is a good place to gain inspiration but you need to do some work after. Thankfully, I met the brilliant Rodeo Oswald at the conference; he provided some context that made the concepts easier to understand.
It is befitting that this moment was on the first day of Indaba; it set the pace for what I was to expect for the rest of the one-week conference.
Meeting Luis Serrano
On the same day, I came across Luis Serrano from Serrano Academy. Some years ago I remember regularly turning to Luis’ YouTube videos to properly understand concepts I was struggling to wrap my head around. For example, in 2020 when I was working on a project that required topic modelling I watched Latent Dirichlet Allocation and Gibbs Sampling; the videos were helpful. Hopefully, you can imagine how excited I was to see the man just two seats away from me. I reached out to him and we had quite a chat, talking on topics from the weather in Kigali to what sharing knowledge could mean for someone looking to focus on engineering and research.
The next day, Luis gave a class on Large Language Models. It was a masterclass; his slides, metaphors, and how kept his audience engaged. I am usually inspired when I see someone do what they know how to do well, it shows that they put in great effort over a long time. As I write this, I wonder if I should try re-explaining the concepts with the metaphors he used, but it’s just sunrise and I don’t need a rabbit hole today.
I will mention two metaphors that I liked from his class:
- Explaining the concepts of Keys and Queries in the attention mechanism via the relationship between himself (less popular) and Taylor Swift (extremely popular).
- Explaining why angular distance is more favourable for measuring vector similarity (compared to Euclidean distance), via how Google Maps measures distance between places.
On the third day, Luis gave a mentorship session. In this class, he gave direct answers to questions, acknowledging when he really didn’t have an answer and using metaphors that did a good job of passing his message across. I will leave you with a gem he shared during the session in relation to the constant uncertainty about doing work in the Artificial Intelligence space.
It goes thus:
“Imagine a sport will be invented in 10 years’ time and you have no idea what that sport will be. How will you prepare?”
The answer from the audience and himself went something like:
“You will probably do a lot of running, swimming, throwing, skipping, jumping, eating healthy. When the sport is finally invented, it will most likely involve some of these things and you will only need a couple of weeks or months of very specific practice.”
In the field of Artificial Intelligence, things are constantly being invented. So it is essential to understand the fundamentals, in preparation for the future and to build the capacity for making contributions. For someone involved in engineering and research, the fundamentals here may include things like: learning to code, knowing linear algebra, knowing how backpropagation works, learning to train a neural network, etc.
Realizing Data Access is Harder Than Initially Thought
I understand that working on data solutions for African problems is hard, but conversations with other attendees helped me see that:
- I was not alone in feeling that way.
- It is much harder than I thought.
In the last couple of years, my interests have been in the areas of information retrieval and natural language processing. So most of the challenges I face are due to the lack of access to documents in Africa’s native languages. There are a dizzying number of languages spoken across the continent; Wikipedia says it is about 2000 to 3000 languages. A lot of those languages do not have a significant digital footprint, so it is hard to build for those languages. These challenges make you question if it is even a worthwhile commitment to try at all.
Outside the language field, others shared frustrations getting access to data in the healthcare, legal, real estate, climate, media spaces. Some of the challenges include:
- The absence of an aggregated, quality data source for the African context. Perhaps seeking one data source is an overkill, but having a couple where the data is of enough quality and quantity to do downstream work such as building products, will go a long way.
- The shortage of funding for data collection. As a result, seeking funding from organizations outside the continent becomes an appealing option, despite the onerous clauses that might be involved.
Africa has a long way to go and the development of infrastructure—whatever that may mean—is a prerequisite to building data solutions. The problems stated above occur even within individual countries, so it will be much harder to get solutions that work across the continent for the ideal Pan-African dream. It was also discussed how the challenge in cross-collaboration further extends even to travel, where you often have to take flights to Europe and then back into Africa to go from one African country to another.
I consider the conversations on this topic to be a top five moment because I rate awareness highly. As more people become aware of the situation, perhaps more efforts can come together that can move the needle. A different article will be needed to talk about what such efforts might be.
Random Learnings
African Institute for Mathematical Sciences (AIMS)
AIMS is a postgraduate school for mathematical sciences. This year’s Indaba is not my first time hearing about the organization, but it is only now that I realize how much impact it is having on the African Artificial Intelligence ecosystem. If it is properly run and gets adequate funding, it can only get better from here. I met a number of students from the institution, likely because there’s a centre in the country: AIMS Rwanda. Most of these students recently finished their Master’s programme there and I met one who is currently doing a PhD. While I do not know enough about the organization to confidently recommend them, I saw enough to say “check them out.”
The Africa Technology Policy Tracker
The Africa Technology Policy Tracker is a platform that keeps track of the various laws, policies and regulations in relation to information technology in Africa, going back to the early 2000s. It seems to contain links to each document and can be useful for individuals looking to do policy research across various African countries. A few links do not work or point to the wrong thing, but most of them work and it is a valuable resource.
Middle East and North Africa Machine Learning (MENA ML)
MENA ML is a Machine Learning Winter School program that appears to hold in January each year. I met someone who attended this year’s edition in Qatar and absolutely loved it. The 2026 edition will be at the King Abdullah University of Science and Technology (KAUST) in the Kingdom of Saudi Arabia. Applications are now open and close on the 18th of September 2025, so hurry and put in your application if interested.
The 10 o’Clock Problem
Open your favourite “chat app” or visual language model, ask it to generate a clock at some time, see what happens. In my case, all images I got had one hand pointing to 10 despite using different prompts. The following grid contains images from: Manus.ai, ChatGPT, Claude, Gemini, stable-diffusion-v1-5, using the following prompt: “Generate an image of a clock at 9pm.”

The only different result is from Claude and it is not because Claude is better. It did not generate an image directly. Instead, it generated an SVG file and rendered it.
Why are the results like this? I don’t know. But my suspicions align with those from the organizers of the GenAI practical sessions at the Indaba: Somewhere in the training process, a lot of clocks with the short hand at 10 and the long hand at 2 were used in the training data.
I find it interesting, and think this is a good example that shows that these models can only pull from their distribution. If the distribution does not “support” your prompt, it does not matter how good your prompt is.
Google DeepMind’s Habermas Machine
On attending Verena Rieser’s keynote speech, "Whose Gold? Aligning AI with Diverse Views on What's Safe, Aligned, and Beneficial", I got to learn about the Habermas Machine. It is system for automated mediation, named after German social theorist Jurgen Habermas. From my understanding, the system tries to answer the question: “Given a group of differing opinions about a matter from various parties, how can you automatically mediate and produce a single useful statement that satisfies the various parties?” I will not be writing about this system in this article, but I recommend Nicholas Kees’ article on the work, it is a lovely overview of the work.
Google’s Healthcare Models
I attended the Data Science for Health Workshop and it included a hands-on tutorial using a couple of Google’s models for Health use cases. These include the MedGemma, MedSigLIP and TxGemma Chat models. These models are quite useful and have a wide range of applications. For example, MedGemma can be used for things like describing an X-ray, MedSigLIP for creating dense embeddings from medical images to be stored in a database like Ahnlich and TxGemma Chat for predicting properties of therapeutics.
Continual Learning
Prior to the Indaba, I did not know “continual learning” was a thing, so the first time I heard it, I actually thought it was “online learning”. As it turns out, they are completely different things. Online learning involves continuously improving a model as new data streams in, rather than storing the data to set up a full retraining process on the entire batch. Continual learning on the other hand, involves training a model such that it retains historical information, essentially tackling the problem of catastrophic forgetting.
A couple of poster presentations at the Indaba were related to continual learning. I remember one talking about latent replay buffers; sadly, I can’t find links to the poster. I also saw one with the title “Ask and Remember: A Questions-Only Replay Strategy for Continual Visual Question Answering” from Imad Eddine Marouf. You can checkout the paper from Imad’s work, and the poster too. Heads-up that there’s a chance the poster link will be broken in the future.
Interestingly, I experienced the case of catastrophic forgetting while working on the project I presented at the Indaba, so I’m curious to try out continual learning techniques:
- To get better context and learn something.
- To see if it works.
Take a look at the following image:
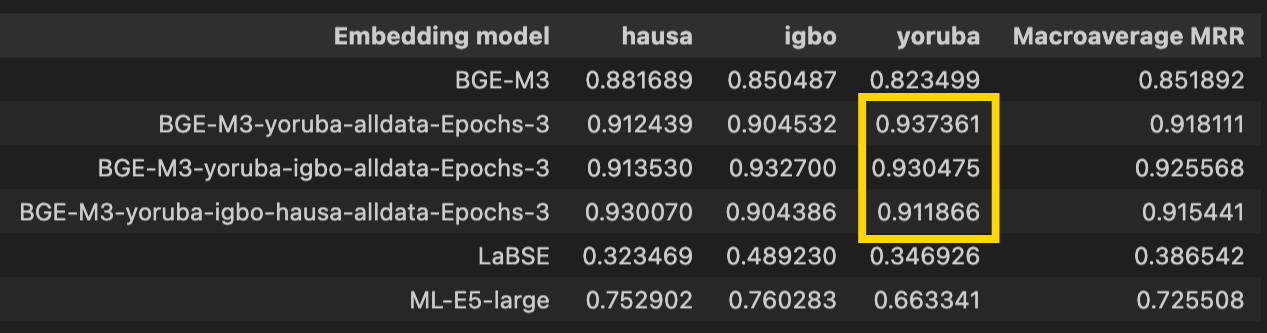
The BGE-M3-yoruba-alldata-Epochs-3 row was the first model training phase, where it was trained on Yoruba only. Next it was trained on Igbo to yield BGE-M3-yoruba-igbo-alldata-Epochs-3. Finally, it was trained on Hausa to yield BGE-M3-yoruba-igbo-hausa-alldata-Epochs-3.
As the model trains on more languages, the quality of the results on Yoruba tasks drops. The Igbo dataset here was probably about 20k rows and the Hausa one about 85k rows. You will notice that the model performs worse after training on Igbo, then takes a huge dip after training on Hausa (4 times the size of the Igbo dataset). Perhaps I’ll write a piece if I ever get around trying different continual learning techniques on this task.
Getting a Poster Award
At ML Collective Nigeria, I suggested setting up an Information Retrieval focus group for members interested in working on projects at the intersection of Information Retrieval and Machine Learning. Interestingly, a couple of incredible people showed interest. The project "Improving BGE-M3 Multilingual Dense Embeddings for Nigerian Low-Resource Languages" was the first project we worked on, and interestingly, the work got a poster award.
You can view the poster presentation on Google Drive, also I will give a brief explanation of the work.
To start with, here’s some context about the base model:
The project builds on the BGE-M3 model. BGE-M3 is an embedding model that supports the creation of embeddings across up to 100 languages, with various forms of embeddings (sparse, dense and multi-vector), and can process up to 8k tokens. You can take a look at the paper, I think it is quite interesting research and engineering-wise. For example, how they use self-knowledge distillation to train for the sparse, dense and multi-vector embedding objectives, and how they batch their data for efficient use of GPU compute.
Back to the work:
The team thought to improve on the quality of BGE-M3 for Nigerian languages. This means if such a model works well enough, it has search use cases in those languages, serving people who speak them as their main language. For example, if one sends text messages in Igbo, it becomes possible to effectively search past text messages. Most software that support search today, do so in English; this is problematic because the user often has to rely solely on keywords that appear in the documents.
So with this model, it is possible to do:
- Yoruba queries to search Yoruba documents
- Igbo queries to search Igbo documents
- Hausa queries to search Hausa documents
Towards the end of the project, the team also wanted to make English queries work semantically, so you can search in English without the keywords appearing in the target document. This kind of search benefits users who want to search within local language documents, but only know English.
The main challenges faced in this work include, but are not limited to:
- Getting data to train the model.
- Building a data cleaning pipeline to reduce the amount of crap we train on.
- Finding an LLM suitable for translating from our target languages to English.
- Efficiently run LLM inference for the translation tasks on the training data.
I used Manus.ai to vibecode the demo below. It shows the English-Yoruba search use case, with our model running in the background.
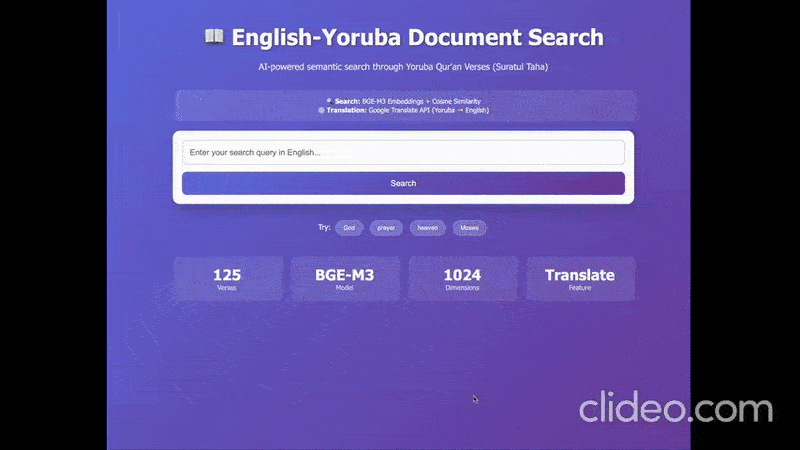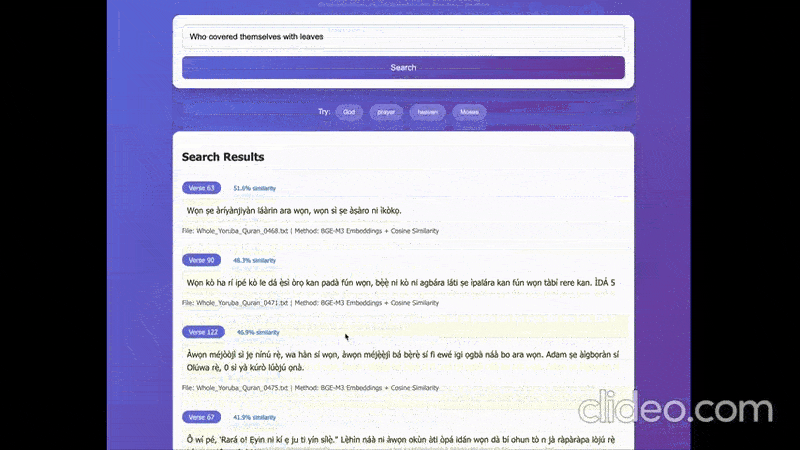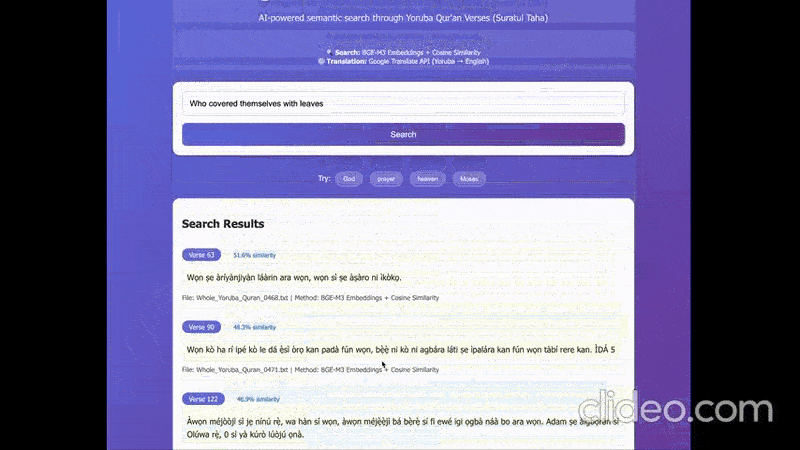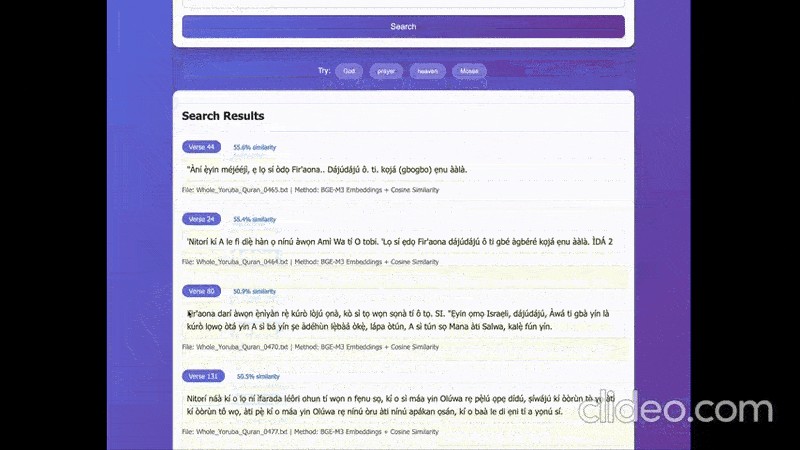
The demo involves the following things:
- Indexing Surah Taha from the Yoruba Qur’an using the embedding model.
- Generating embeddings with the English query using the embedding model.
- Using cosine similarity to find the most similar verses to the query.
- Generating translations from Yoruba to English for highlighted text (the translations generally don’t make sense but are useful here).
I did this using Manus.ai and I was quite impressed by the results. I think a PoC like this is a good use case for vibecoding, as I do not care if it does things the correct way, as long as it works. You can find the prompt I used in this GitHub Gist if interested.
The End
That’s all I have to share in this article about my top five moments at the Deep Learning Indaba 2025 in Rwanda. If you are still reading, I hope you benefitted a thing or two from the piece. As a reward 😂, you can find the Colab notebooks used at the practical sessions at the Indaba at indaba-pracs-2025 on GitHub.
See you in the next one.



Leave a comment